
The previous blog post looked at the basics of converting text into vectors using TF-IDF.
From TF-IDF we can now use Cosine Similarity to find documents which match a query.
In the previous post we used the example of extracting text from a PDF. We converted words into vectors from the pdf. Now when we put a query, it takes each word from that query and converts it into a vector. Then it sees how close the query vector matches the database of vectors we have.
Cosine similarity is the dot product of the vectors divided by their magnitude. For example, if we have two vectors, A and B, the similarity between them is calculated as:
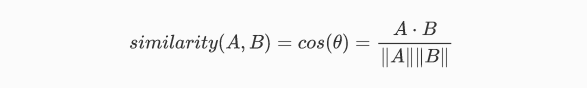
The similarity can take values between -1 and +1. Smaller angles between vectors produce larger cosine values, indicating greater cosine similarity. For example:
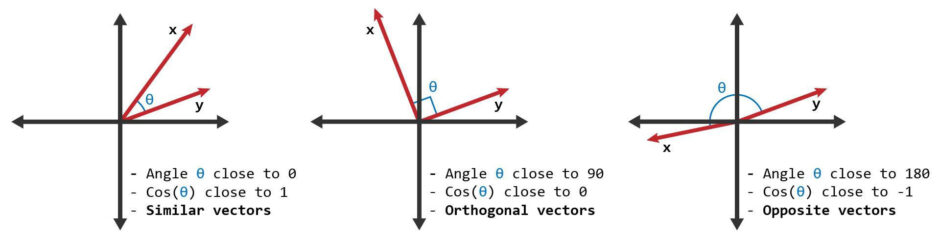
- When two vectors have the same orientation, the angle between them is 0, and the cosine similarity is 1.
- Perpendicular vectors have a 90-degree angle between them and a cosine similarity of 0.
- Opposite vectors have an angle of 180 degrees between them and a cosine similarity of -1.
Graphically it can be shown as below:
So based on this, if we put a query of “What is atmospheric pressure?” against the sample physics pdf, we get the top 5 vectors which have the best matching scores. Each index is the page number in the pdf where it finds the match,
Querying top 5 documents for [‘What is atmospheric pressure’]
Top related indices:
[ 935 652 1126 1242 220]
Corresponding cosine similarities
[0.34417706 0.28845559 0.28715727 0.23502315 0.22972955]
So what we have now is a very basic search engine which returns results based on similarity of the query to the existing data. There are two big limitations in cosine similarity:
1.It only considers the angle between two vectors, ignoring their magnitudes. As a result, a long page with many words can have the same importance as a short page with few words but similar content.
2.It only measures frequency and has no idea of context and semantics of the words, thus making it a little dumb.
For the model to get intelligence, we will apply a BERT transformer to the data corpus. BERT (Bidirectional Encoder Representations from Transformers) was developed by Google and it pre-trains deep bidirectional representations from the unlabeled text, conditioning on both the left and right contexts .By doing a BERT transformation, we take into consideration the context of a word by looking at the words to its left and right.
So the context for the word shadow in the two sentences: “He looked at his shadow on the floor” and “He was a shadow of his former self” have completely different contexts. BERT is a contextual model which captures these relationships bidirectionally.

Leave a Reply