
This is a three part blog which looks into the very basics of processing text into vectors, which can then be used for contextual search.
The first step is to convert the contents of a PDF into a format which can then be processed and analysed. Basically we are converting all the words and sentences into numbers. Each word is a term and each page in the pdf is a document. So TF-IDF (Term Frequency-Inverse Document Frequency) is a statistical process to convert text data into vectors and is based on the relevancy of the words. It creates a matrix for the least and the most relevant words in the document.
TF is the ratio of the occurrence of the word (w) in document (d) per the total number of words in the documents. With this simple formulation, we are measuring the frequency of a word in the document. if a sentence has 6 words and contains two “the”, the TF ratio of word “the” would be (2/6).

A corpus is a collection of documents. For example, a pdf is a corpus with each page being a document. IDF calculates the importance of a word in a corpus D. The most frequently used words like “of, we, are” have little to no significance. It is calculated by dividing the total number of documents in the corpus by the number of documents containing the word.
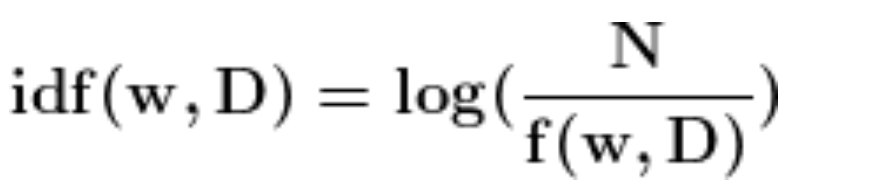
TF-IDF is the product of term frequency and inverse document frequency. It gives more importance to the word that is rare in the corpus and common in a document.
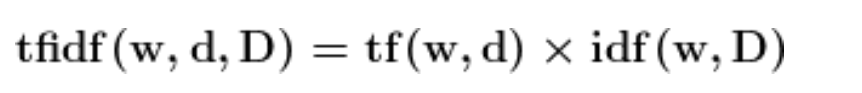
So if we take a sample pdf and extract the text from it as page with each page being saved as an individual file,we end up with something like this.
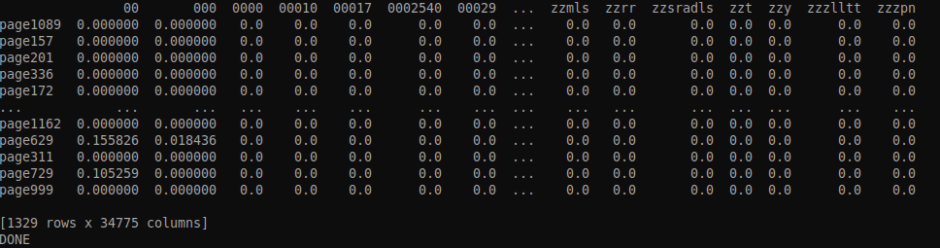
If we take the book which has around 1300 pages and we run the TF-IDF generator code, what we end up with is a matrix with the rows representing the score of words in a single document. The columns are the scores of each word across all the documents(pages).
In the screenshot below, since there are over 30k columns of words, it is only showing the starting words and the ending words sorted alphabetically. It considers numbers also as words so they come first and the last columns have words starting with z.
The next stage will be to enable this matrix to be searchable so that it can find matching documents for a search query. For that we will be looking at Cosine Similarity.
Leave a Reply