
1.Run sudo apt update to make sure all packages are updated to the latest versions
2.Run sudo apt install build-essential to install the toolchain for building applications using C++
3.Create a directory to setup llama.cpp:
mkdir /var/projects
cd /var/projects
4.Get the llama.cpp code from Github:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
5.Verify that nvidia drivers are present in the system by typing the command:
sudo ubuntu-drivers list OR sudo ubuntu-drivers list –gpgpu
You should get a listing similar to the output below:
nvidia-driver-390, (kernel modules provided by linux-modules-nvidia-390-generic)
nvidia-driver-535, (kernel modules provided by linux-modules-nvidia-535-generic)
nvidia-driver-470, (kernel modules provided by linux-modules-nvidia-470-generic)
nvidia-driver-418-server, (kernel modules provided by nvidia-dkms-418-server)
nvidia-driver-450-server, (kernel modules provided by linux-modules-nvidia-450-server-generic)
nvidia-driver-535-server, (kernel modules provided by linux-modules-nvidia-535-server-generic)
nvidia-driver-470-server, (kernel modules provided by linux-modules-nvidia-470-server-generic)
nvidia-driver-545, (kernel modules provided by nvidia-dkms-545)
6.Update the nvidia drivers in the current Ubuntu installation:
sudo ubuntu-drivers install
7.Reboot the system for the drivers to take effect
sudo shutdown -r now
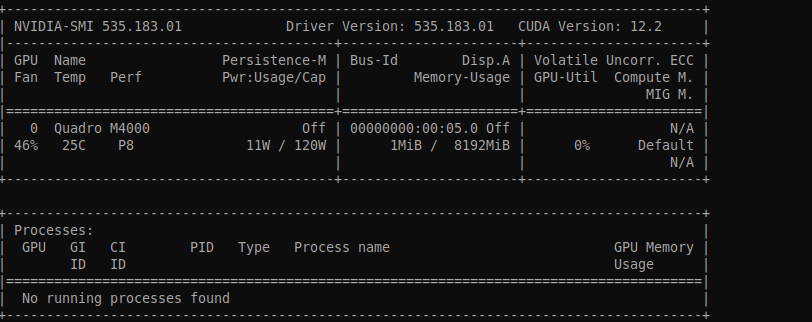
8.After rebooting, verify that nvidia is active by the command:
nvidia-smi
You should get a similar output as below:
9.Install gpustat utility:
sudo apt install gpustat
10.Run gpustat. You should get a similar output as below:

11.Install the NVCC compiler with the command:
sudo apt install nvidia-cuda-toolkit
12.Before we can build llama.cpp we need to know the Compute Capability of the GPU:
nvidia-smi –query-gpu=compute_cap –format=csv
This will give a single score eg 3.0, 5.2 etc.
13.Set the Compute Capability score in the shell by typing:
export CUDA_DOCKER_ARCH=compute_XX where XX will be the score (without the decimal point) eg. export CUDA_DOCKER_ARCH=compute_35 if the score is 3.5
14.Next step is to build llama.cpp:
cd /var/projects/llama.cpp
make GGML_CUDA=1
15.This completes the building of llama.cpp. Next we will run a quick test to see if its working
16.We download a small gguf into the models folder in llama.cpp:
cd models
wget https://huggingface.co/afrideva/Tiny-Vicuna-1B-GGUF/resolve/main/tiny-vicuna-1b.q5_k_m.gguf
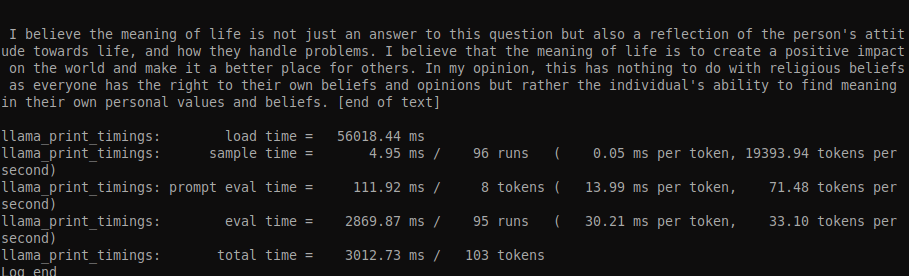
17.We run a test query from the llama.cpp root folder
./llama-cli -m models/tiny-vicuna-1b.q5_k_m.gguf -p “I believe the meaning of life is” -n 128 –n-gpu-layers 6
You should get an output similar to the output below:
On item #12, it’s nvidia-smi -–query-gpu=compute_cap –-format=csv (note the double hyphens)
Yes the double hyphen somehow got clobbered by wordpress. I have fixed it
On item #17, it’s ./llama-cli -m models/tiny-vicuna-1b.q5_k_m.gguf -p “I believe the meaning of life is” -n 128 –n-gpu-layers 6 (note the double hyphen)